Data Preparation
Input files are accepted in .tsv file format - as text files with tab-separated columns.

Requirements:
- the file must have 2 or 3 columns, depending on whether you have event timestamps - see Option 1: Database export without timestamps and Option 2: Database export with timestamps)
- the fixed ordering of columns is mandatory
- the file must be tab-separated. Using Pandas, save with
sep='\t'. - the file should have a header (column names). The first line is interpreted as a header. Using Pandas, save with
header=True. - the file should NOT have an index. Using Pandas, save with
index=False. - integer numeric values are preferred in Column 1 and Column 2, due to anonymization. You probably want to assign some hash identifiers, instead of using real textual values. Cleora does not need text, integer identifiers are fully sufficient.
A well-formatted, working example input file can be downloaded from here.
Option 1: Database export without timestamps
In the simplest case, you need a 2-column extract from your database. The IDs within the columns can (and probably should be) anonymized. Each row expresses an event - the fact that a certain user ID interacted with a product ID at a given point in time.
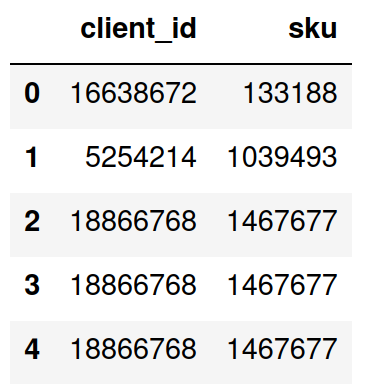
Input file creation with Pandas:
>>> df.columns
Index(['client_id', 'entity_id'], dtype='object')
>>> df.dtypes
user_id int64
product_id int64
>>> df.to_csv('cleora_input.tsv', sep='\t', header=True, index=False)
Column 1 will give Cleora a key for grouping (which is used to create edges in the graph). This will usually be user IDs, session IDs, shop IDs, invoice IDs or other similar entities which represent some approach towards grouping the entities from Column 2.
Column 2 will be embedded - you will obtain embeddings for each entity which appears in this column. These will usually be product IDs, brand IDs, category IDs, or other entities your users are interacting with.
Option 2: Database export with timestamps
Optionally, you can also use a 3-column format with a timestamp column. The logic is the same as in the 2-column format, but the 3rd column additionally has a timestamp for each event.
Timestamps allow Cleora to use more detailed temporal relations for edge creation in the graph, potentially increasing embedding quality.
Your input file should look like this:
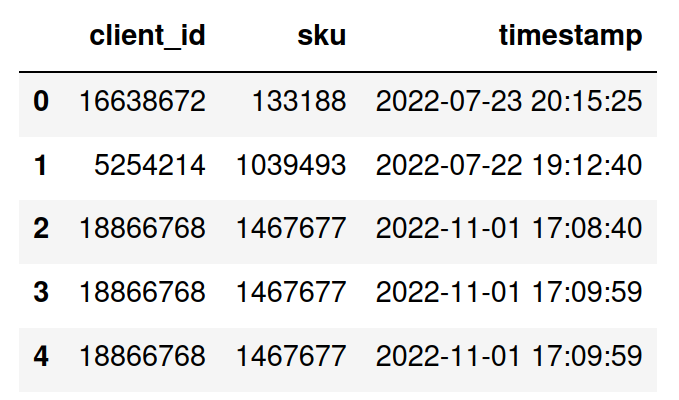
Input file creation with Pandas:
>>> df.columns
Index(['client_id', 'entity_id', 'timestamp'], dtype='object')
>>> df.dtypes
user_id int64
product_id int64
timestamp object
>>> df.to_csv('cleora_input.tsv', sep='\t', header=True, index=False)
Supported datetime formats:
| Datetime Format | Example |
|---|---|
| Y-m | 2024-02 |
| Y-m-d | 2024-02-01 |
| d/m/Y | 01/02/2024 |
| m/d/Y | 02/01/2024 |
| b d, Y | Feb 01, 2021 |
| B d, Y | February 01, 2024 |
| Y-m-d H:M | 2024-02-01 07:00 |
| Y-m-d H:M:S | 2024-02-01 07:00:00 |
| Y-m-dTH:M:S | 2024-02-01T07:00:00 |
| Y-m-dTH:M:SZ | 2024-02-01T07:00:00Z |
| Y-m-d H:M:Sz | 2024-02-01 07:00:00+00:00 |
If your datetime format is outside of this list, Cleora will try to parse it anyway, but success is not guaranteed.