Application of Embeddings
Embeddings represent various important aspects of entities. Usually, similar entities are represented by vectors which are close by in the embedding space.
Similar Entity Search
Embeddngs are a perfect tool for similar entity search. Entities which behave in a similar way are usually close by in the embedding space. All that is needed is to compute the cosine distance between embeddings. Or, for visual inspection, we can apply a good dimensionality reduction technique - for example, UMAP.
In the following example, we will use the dataset from the REES46 Marketing Platform https://rees46.com/ which is freely available at https://www.kaggle.com/datasets/mkechinov/ecommerce-behavior-data-from-multi-category-store. The same example can be found in the Tutorial within Cleora platofrm. We embed the product brands.
Consider these 3 companies, all producing projectors:
- Cinemood
- Optoma
- Xgimi
We can see that their Cleora embedding vectors are located very close to each other. This means that with Cleora, we can easily discover that they operate a similar business.
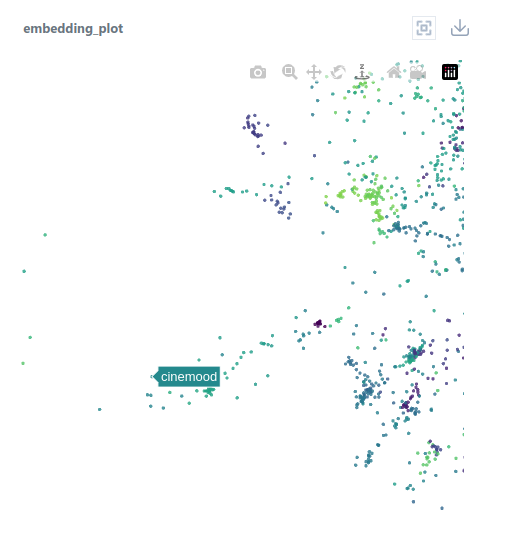


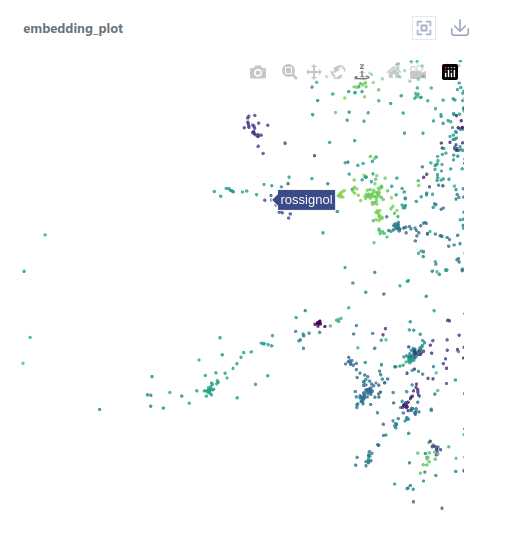
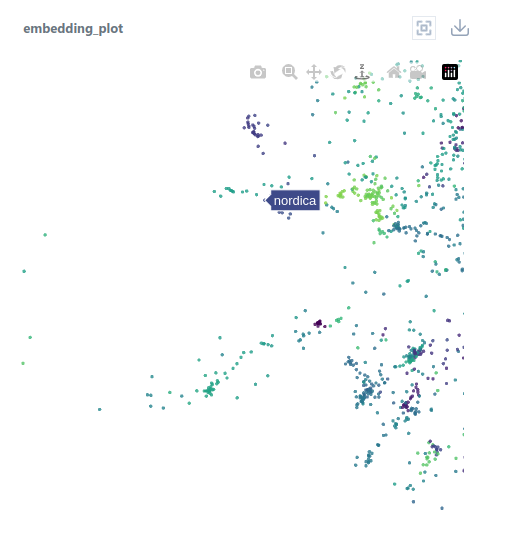
Other types of companies are located elsewhere in the embedding space. For example, companies Rossignol and Nordica, which produce winter sports gear, are located in a totally different cluster.
Embeddings as Input to ML Models
Embeddings are used in the most wide-spread approaches towards modeling recommendation, propensity, churn, and other predictive tasks for user behavior.
Usually, 2 types of embeddings are needed: user embeddings and item/category/brand/... embeddings. Item embeddings are computed straight away by algorithms such as Cleora. User embeddings are constructed from item embeddings they have interacted with. Depending on available resources, some of the following approaches are possible:
- Represent the user with the embedding of the last item/brand/category/... they interacted with
- Represent the user with an average of item/brand/category/... embeddings they interacted with
- Use an ML model which can process the sequence of embeddings or a set of embeddings:
- EMDE https://github.com/BaseModelAI/EMDE
- Gru4Rec https://github.com/hidasib/GRU4Rec_PyTorch_Official
- Graph Neural Networks
Fixed user and item embeddings give many advantages performance-wise. For example, it is possible to store similarity scores between user representations and item embeddings, instead of whole embeddings. Similarly, it is possible to store similarity scores between pairs of item embeddings. Such similarity scores can be stored for a limited number of most similar pairs. Thanks to this, storage of very long embeddings becomes unnecessary, and similarity scores are computed only once for each embedding version, which saves time and resources.
Interesting approaches are presented for example in these papers:
- "Embedding-Based News Recommendation for Millions of Users", Shumpei Okura, Yukihiro Tagami, Shingo Ono, and Akira Tajima https://dl.acm.org/doi/10.1145/3097983.3098108
- "Billion-Scale Commodity Embedding for E-Commerce Recommendation in Alibaba", Jizhe Wang, Pipei Huang, Huan Zhao, Zhibo Zhang, Binqiang Zhao, and Dik Lun Lee https://arxiv.org/pdf/1803.02349.pdf
- "Beyond Two-Tower Matching: Learning Sparse Retrievable Cross-Interactions for Recommendation" https://dl.acm.org/doi/abs/10.1145/3539618.3591643